24小時從0到1開發(fā)陰陽師小程序
0.序玩陰陽師的肝帝們都知道,每天早上5點和下午6點會刷新兩次封印任務(wù),每次做任務(wù)時最蛋疼的就是找各種怪物對應(yīng)的副本以及神秘線索。 陰陽師提供了 網(wǎng)易精靈 可以進行 ...
0.序
玩陰陽師的肝帝們都知道,每天早上5點和下午6點會刷新兩次封印任務(wù),每次做任務(wù)時最蛋疼的就是找各種怪物對應(yīng)的副本以及神秘線索。 陰陽師提供了 網(wǎng)易精靈 可以進行一些數(shù)據(jù)查詢,但體驗實在太感人,所以大多數(shù)人選擇使用搜素引擎搜索怪物分布及神秘線索。
而每次使用搜索引擎查找又十分不方便,所以筆者決定寫一個查詢陰陽師妖怪分布的小程序,力求做到使用快捷體驗更快捷,把更多的時間留給狗糧和御魂。
恰好上周末有兩天時間,所以立馬開寫。
1.構(gòu)思與設(shè)計 ( 3小時 )
1.1 構(gòu)思
- 要做的小程序主要功能就是查詢功能,所以主頁應(yīng)該像搜索引擎一樣簡潔,搜索框是肯定需要的;
- 主頁包含熱門搜索,緩存最熱式神的搜索;
- 搜索支持完整匹配或者單字匹配;
- 點擊搜索結(jié)果直接跳轉(zhuǎn)到式神詳情頁;53. 式神詳情頁應(yīng)該包含式神的圖鑒、名稱、稀有度、出沒地點,并且出沒地點按妖怪?jǐn)?shù)量從多到少排序;
- 加入數(shù)據(jù)報錯及提建議的功能;
- 支持用戶個人的搜索歷史;
- 小程序的名字,綜合考慮小程序的功能最后決定叫做 式神獵手 ( 其實這是最后開發(fā)完成后才想好的 );
1.2 設(shè)計
構(gòu)思好后筆者就開始用筆者半吊子的 PS 水平設(shè)計了下草圖,大概是這個樣子:
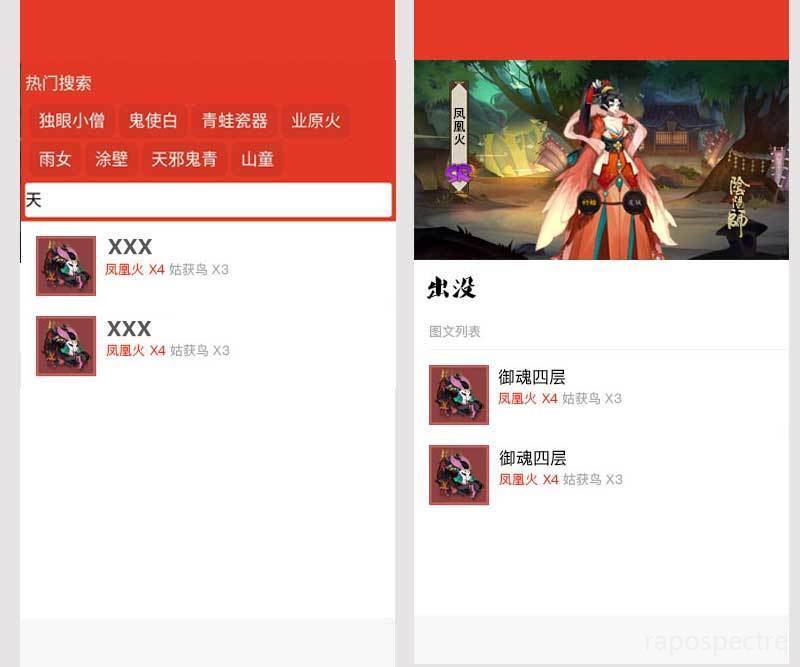
嗯,最主要的首頁和詳情頁設(shè)計好就行,然后就可以開始具體考慮怎么做了!
1.3 技術(shù)架構(gòu)
- 前端毫無疑問就是微信小程序咯;
- 后端使用 Django 提供 Restful API 服務(wù);
- 當(dāng)前最熱搜索用 redis 做緩存服務(wù)器進行緩存;
- 個人搜索記錄就使用微信小程序提供的 localstorage ;
- 式神分布信息使用爬蟲爬取清洗,格式化為 json , 入庫前再做人工檢查;
- 式神圖片及圖標(biāo)直接爬取官方資料;
- 自己制作爬不到的式神圖片及圖標(biāo);
- 小程序要求 HTTPS 連接,恰好筆者之前搞過,可以直接看這里 HTTPS 免費部署指南
到此,正式開發(fā)前的準(zhǔn)備得當(dāng)后,我們就可以開始正式開發(fā)了
2. API 服務(wù)開發(fā) ( 5小時 )
Django 的 API 服務(wù)開發(fā)筆者之前經(jīng)常做,所以有比較完整的解決方案,可以參考這里django-simple-serializer
之所以花了 5 個小時是因為近 4 個小時在增加 django-simple-serializer 對 Django ManyToManyField 中 through 特性的支持。
簡而言之, through 特性就是可以使多對多關(guān)系的中間表增添一些額外的字段或?qū)傩裕? 怪物副本和怪物之間的多對多關(guān)系就需要增加一個儲存每個副本有多少只相應(yīng)怪物數(shù)量的字段 count。
搞定 through 支持后 API 的構(gòu)建就很快啦,主要有五個 API :
- 搜索接口;
- 式神詳情接口;
- 式神副本接口;
- 熱門搜索接口;
- 反饋接口;
寫好接口后添加一些 mock data 以供測試;
3. 前端開發(fā) ( 8小時 )
前端花了最久的時間。
一方面筆者真的是個后端工程師,前端屬于半路出家,另一方面小程序有一些坑。 當(dāng)然,最主要的是一直在調(diào)整界面效果,這里花了大量時間。
寫小程序的整體體驗筆者感覺就和寫 vue.js 一摸一樣,只不過一些 html 標(biāo)簽沒辦法使用,而是需要按小程序官方提供的組件進行書寫, 這里有一點感受就是,小程序本身組件化的設(shè)計思路應(yīng)該是借鑒了 React 而語法之類的應(yīng)該是借鑒了 vue.js 。
最后前端開發(fā)完畢后主要分為這幾個頁面:
- 主頁 ( 搜索頁 );
- 式神詳情頁;
- 我的頁面 ( 主要是放搜索歷史和免責(zé)申明等等東西 );
- 反饋界面;
- 聲明界面 ( 為何需要這個界面? 因為所有圖片及一些資源都是直接抓取陰陽師官方的資源,所以這里需要申明只是非盈利性質(zhì)的使用,版權(quán)亂七八糟的都還是陰陽師的 )。
哎,丑媳婦早晚要見公婆,這里不得不放最后開發(fā)出來的界面圖了
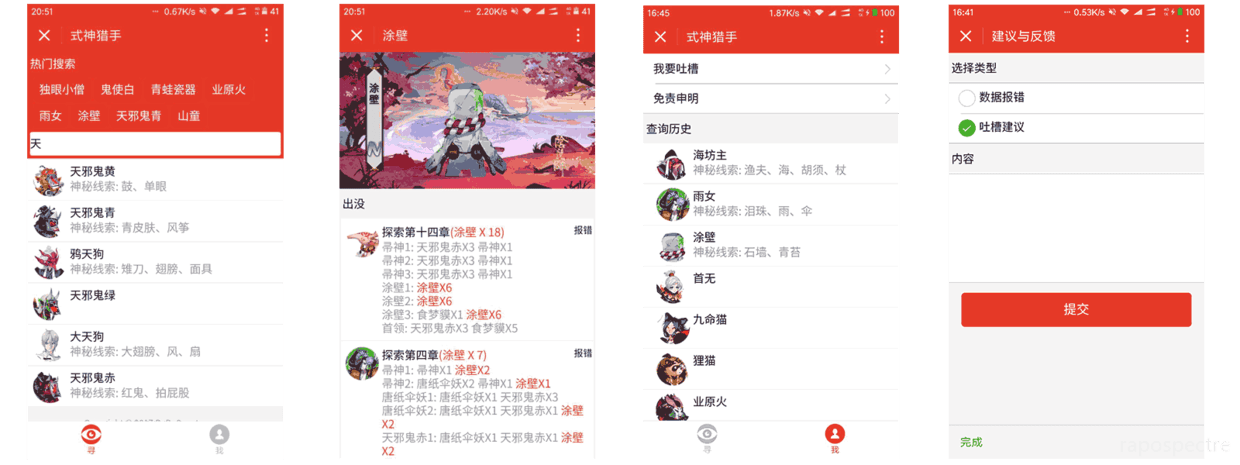
對于微信小程序的入門及基礎(chǔ),筆者就不在這里多講了,相信到現(xiàn)在對微信小程序有關(guān)注的開發(fā)者或多或少自己寫個簡單的 demo 肯定是沒問題的,我就主要講一講我在開發(fā)中遇到的坑:
3.1 background-image 屬性
在寫式神詳情頁的時候兩個地方需要用到 background-image 屬性設(shè)置背景圖,在微信開發(fā)者工具中一切顯示正常,但一到真機調(diào)試就沒有辦法顯示,最后發(fā)現(xiàn)小程序的 background-image 在真機不支持引用本地資源,解決方案有兩種:
- 使用網(wǎng)絡(luò)圖片: 考慮到背景圖的大小,筆者放棄了這種方案;
- 使用 base64 編碼圖片。
正常來講,css 中的 background-image 就支持 base64 ,這種方案相當(dāng)于把圖片直接用 base64 編碼成一段 base64 碼進行儲存,在使用時這樣使用即可:
background-image: url(data:image/image-format;base64,XXXX);
image-format 為圖片本身的格式,而 xxxx 就是圖片經(jīng)過 base64 后得到的編碼。這種方式其實是一種變相引用本地資源的方式,好處在于可以減少請求圖片的次數(shù),而缺點則是會增大 css 文件并使其不是那么好看。
最后筆者選擇第二種方式主要還是考慮到圖片的大小以及 wxss 的增大在可接受范圍內(nèi)。
3.2 template
小程序支持模版,但要注意模板擁有自己的作用域,只能使用data傳入的數(shù)據(jù)。
另外,在傳入數(shù)據(jù)時需要將相關(guān)數(shù)據(jù)解構(gòu)傳入,在模版內(nèi)部是直接以 {{ xxxx }} 的形式進行訪問,而不是像在循環(huán)中 {{ item.xxx }} 這種訪問形式;
關(guān)于解構(gòu):
<template is="xxx" data="{{...object}}"/>
三個 . 就是解構(gòu)操作;
一般 template 都會放在 單獨的 template 文件中讓其他文件進行調(diào)用,而不會直接寫在正常的 wxml 中。 比如筆者目錄大概是這樣的:
├── app.js
├── app.json
├── app.wxss
├── pages
│ ├── feedback
│ ├── index
│ ├── my
│ ├── onmyoji
│ ├── statement
│ └── template
│ ├── template.js
│ ├── template.json
│ ├── template.wxml
│ └── template.wxss
├── static
└── utils
關(guān)于其他文件調(diào)用 template,直接使用 import 即可:
<import src="../template/template.wxml" />
然后在需要引用模版的地方:
<template is="xxx" data="{{...object}}"/>
<!--is 后填寫模版名稱-->
這里遇到另一個問題,template 對應(yīng)的樣式寫在 template 對應(yīng)的 wxss 中并沒有作用,需要寫在調(diào)用 template 的文件的 wxss 中,比如 index 需要使用 template 則需要將對應(yīng)的 css 寫在 my/my.wxss 中。
4. 爬取圖片資源 ( 2小時 )
式神的圖標(biāo)及形象圖基本上陰陽師官網(wǎng)都有,這里自己做也不現(xiàn)實,所以果斷寫爬蟲爬下來然后存到自己的 cdn 。
大圖和小圖都在 http://yys.163.com/shishen/index.html 這里可以找到。 一開始考慮爬取網(wǎng)頁然后 beautiful soup 提取數(shù)據(jù),后面發(fā)現(xiàn)式神數(shù)據(jù)竟然是異步加載的,那就更簡單了,分析網(wǎng)頁得到 https://g37simulator.webapp.163.com/get_heroid_list 直接返回了式神信息的 json 信息,所以很容易寫個爬蟲就可以搞定了:
# coding: utf-8
import json
import requests
import urllib
from xpinyin import Pinyin
url = "https://g37simulator.webapp.163.com/get_heroid_list?callback=jQuery11130959811888616583_1487429691764&rarity=0&page=1&per_page=200&_=1487429691765"
result = requests.get(url).content.replace('jQuery11130959811888616583_1487429691764(', '').replace(')', '')
json_data = json.loads(result)
hellspawn_list = json_data['data']
p = Pinyin()
for k, v in hellspawn_list.iteritems():
file_name = p.get_pinyin(v.get('name'), '')
print 'id: {0} name: {1}'.format(k, v.get('name'))
big_url = "https://yys.res.netease.com/pc/zt/20161108171335/data/shishen_big/{0}.png".format(k)
urllib.urlretrieve(big_url, filename='big/{0}@big.png'.format(file_name))
avatar_url = "https://yys.res.netease.com/pc/gw/20160929201016/data/shishen/{0}.png".format(k)
urllib.urlretrieve(avatar_url, filename='icon/{0}@icon.png'.format(file_name))
然而,爬完數(shù)據(jù)后發(fā)現(xiàn)一個問題,網(wǎng)易官方的圖片都是無碼高清大圖,對于筆者這種窮 ds 大圖放在 cdn 上兩天就得破產(chǎn),所以需要批量將圖片轉(zhuǎn)成既不太大又能看的過去。嗯,這里就可以用到 ps 的批處理能力了。
- 打開 ps ,然后選擇爬到的一張圖片;
- 選擇菜單欄上的“窗口”然后選擇“動作;
- 在“動作”選項下,新建一個動作;
- 點擊圓形錄制按鈕開始錄制動作;
- 按正常處理圖片等順序?qū)⒁粡垐D片存為 web 格式;
- 點擊方形停止按鈕停止錄制動作;
- 選擇菜單欄上的 文件-自動-批處理-選擇之前錄制的動作-配置好輸入文件夾和輸出文件夾;
- 點擊確定就可以啦;
等批處理結(jié)束,期間刷個御魂啥的應(yīng)該就好了,然后將得到的所有圖片上傳到靜態(tài)資源服務(wù)器,圖片這里就處理完啦。
5. 式神數(shù)據(jù)爬取 ( 4小時 )
式神分布數(shù)據(jù)網(wǎng)上比較雜并且數(shù)據(jù)很多有偏差,所以斟酌再三決定采用半人工半自動的方式,爬到的數(shù)據(jù)輸出為 json:
{
"scene_name": "探索第一章",
"team_list": [{
"name": "天邪鬼綠1",
"index": 1,
"monsters": [{
"name": "天邪鬼綠",
"count": 1
},{
"name": "提燈小僧",
"count": 2
}]
},{
"name": "天邪鬼綠2",
"index": 2,
"monsters": [{
"name": "天邪鬼綠",
"count": 1
},{
"name": "提燈小僧",
"count": 2
}]
},{
"name": "提燈小僧1",
"index": 3,
"monsters": [{
"name": "天邪鬼綠",
"count": 2
},{
"name": "提燈小僧",
"count": 1
}]
},{
"name": "提燈小僧2",
"index": 4,
"monsters": [{
"name": "燈籠鬼",
"count": 2
},{
"name": "提燈小僧",
"count": 1
}]
},{
"name": "首領(lǐng)",
"index": 5,
"monsters": [{
"name": "九命貓",
"count": 3
}]
}]
}
然后再人工檢查一遍,當(dāng)然還是會有遺漏,所以數(shù)據(jù)報錯的功能就很重要啦。
這一部分實際寫代碼的時間可能只有半個多小時,剩下時間一直在檢查數(shù)據(jù);
一切檢查結(jié)束后寫個腳本直接將 json 導(dǎo)入到數(shù)據(jù)庫中,檢查無誤后用 fabric 發(fā)布到線上服務(wù)器進行測試;
6. 測試 ( 2小時 )
最后一步基本上就是在手機上體驗查錯,修改一些效果,關(guān)閉調(diào)試模式準(zhǔn)備提交審核;
此時已經(jīng)是周日,哦,不對,應(yīng)該是周一早上一點鐘了:
不得不說,小程序團隊審核速度很快啊,周一下午就審核通過了,然后果斷上線。
最后放效果圖:
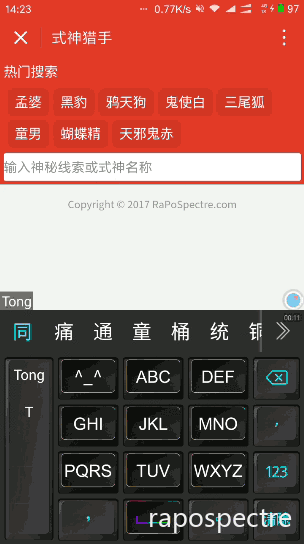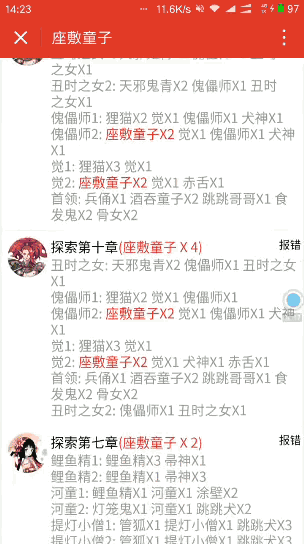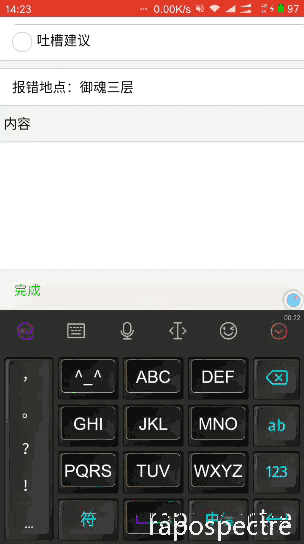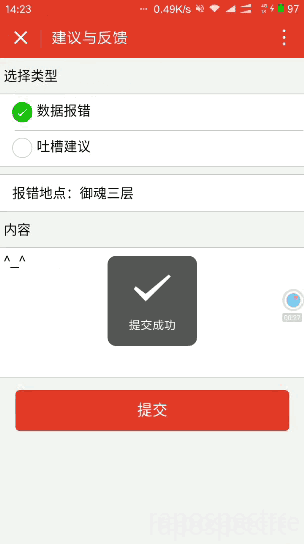
感興趣的同學(xué)歡迎掃碼體驗喲:

手機長按不能進入小程序,需要在 微信-發(fā)現(xiàn)-小程序-搜索-式神獵手 進入
7. 結(jié)尾
以上所有內(nèi)容均已開源,歡迎大家參考:
后端: 式神獵手后端 ( https://github.com/bluedazzle/HellspawnHunterBackend )
小程序端: 式神獵手小程序 ( https://github.com/bluedazzle/hellspawn-hunter-weapp )
API 解決方案: django-simple-serializer ( https://github.com/bluedazzle/django-simple-serializer )



